Solving A Large AWS S3 Data Transfer Challenge With Batch Replication
When Kurtosys decided to go all in using AWS as a cloud vendor it meant a full commitment to pursue both innovative and agile business and operational models.



When Kurtosys decided to go all in using AWS as a cloud vendor it meant a full commitment to pursue both innovative and agile business and operational models. The objective of this modernisation initiative, which should be the goal of all digital transformations, is to create new value for customers, employees, and stake holders.
The theoretical application of transformation is important but without a successful practical implementation, the overall experience can suffer. Practicalities include a customer centric approach by mitigating outages and executing efficiently against a time sensitive and focused roadmap with the ability to remain agile in the face of unforeseen challenges and circumstance. Of course, keeping a check on cost, monitoring implementations to determine success and applying security best practices are essential.
This use case represented an example of a simple theoretical application requiring a more sophisticated implementation. The challenge offered an opportunity to deep dive the requirements and solution offerings.
SIMPLE STORAGE SERVICE (S3) DATA TRANSFERS
AWS’s object level storage, with a vast storage capacity, is called Simple Storage Service or S3. Object containers are represented as buckets. Typical accounts can host hundreds of buckets which could contain hundreds of millions, possibly billions of objects.
The use case required a copy of data from source buckets to destination buckets. This rudimentary task increases in complexity relative to the amount of data in question and whether the data transfer should be persistent, once off or both. Also, whether objects should always exist between the two buckets no matter the source or destination and whether the specified buckets exist in different accounts. Buckets marked for transfer could have a mix of the above listed elements.
REQUIREMENTS
The overall requirement was to guarantee data existed as a dynamic mirror in two locations (source and destination) in preparation for the source resources to be decommissioned and the destination to assume full data responsibilities. This translated into a number of source S3 buckets in a single AWS account that needed new and existing data to be transferred to the corresponding destination S3 buckets in multiple AWS accounts.
A large portion of the implementation challenge is selecting the appropriate solution from the identified offerings. It’s often difficult to cover all the requirements of a solution before identifying and proof testing. Sometimes new requirements or previously unknown limitations crop up even after implementation. These circumstances tend to test agility and grit.
One key requirement was to ensure that any new data arriving at the source was to be immediately copied to the destination. The other key requirement was that all existing data in the source was to be copied to the destination. These requirements were necessary for all buckets involved in this project.
Some, but not all buckets allowed for the deletion of older data. This would reduce the overall bucket size and object count facilitating efficiency and a more cost-effective approach. For example, one large bucket housed data spanning back years. Buckets like this had a requirement of deleting redundant data based on predefined life cycles to ensure only data beyond a certain timestamp was to be removed.
With these requirements identified, we were able to start exploring the solution offerings that met the requirements. As stated earlier, some requirements and limitations remain hidden only to reveal themselves well into the process. This is not uncommon and was certainly the case during our implementation.
SOLUTION OFFERINGS
Based on our initial requirements we settled on a combination of three technologies.
Life cycle policies were applied to some use cases to reduce the amount of objects in the source bucket. The policy was configured to expire objects 60 days after creation with the following actions:
- Expire current versions of objects
- Permanently delete non-current versions of objects
- Delete expired object delete markers or incomplete multipart uploads
Replication was applied to all source buckets to ensure that any new objects are replicated to the destination bucket. The replication is limited to new objects only but this established a method to get new objects transferred in near real time as they arrived in the source bucket.
Data Sync was the technology used to transfer the existing data. Data Sync facilitates the transfer of data for a number of technologies including S3. It can be configured to schedule data transfers with a cron mechanism or one can manually kick off the Data Sync job. With a replication strategy in place on each bucket we realised scheduled syncs were not necessary since a single sync would suffice to transfer all existing objects while the ongoing replication manages anything new. This strategy proved to be cost effective since each time a sync is initiated, a listing of objects is necessary and depending of the number of objects, the cost of this listing procedure can be significant.
CHALLENGES
The chosen solutions met the requirements of the majority of the buckets in question and for buckets with a lower medium of objects these solutions worked well. A challenge arose with our large client consuming, production buckets in our United States and European regions.
To put things in perspective, the combined total of these buckets, of which there were only two, were ~80 TB with ~400 million objects. These buckets did not match the requirement of life cycle policies and therefore it was necessary that all data, spanning back to the creation of the bucket, was to be transferred.
Initially we presumed that Data Sync would be able to manage this amount of data. Well into the implementation phase we discovered that Data Sync had a limitation of 16 million objects per job. This means we would not be able to sync single buckets with data above this limitation with a single sync job.
We contacted AWS support to assist.
The recommended solution was to split the contents of the buckets into separate Data Sync jobs. This would reduce the number of objects per job. The split would be based on grouping bucket prefixes (folders) and applying them to a Data Sync job.
This presented additional challenges like measuring the number of objects per prefix and getting it to match the overall limitation of a job which was 16 million objects.
We were able to utilise S3 Storage Lens to get an indication of the size of each prefix. Many prefixes were well above the limitation size. This meant that we would have to split prefixes within prefixes. This became even more challenging to estimate the size of the splits and quickly realised this particular method was untenable.
We then engaged with AWS support to increase the limitation of a Data Sync job. After multiple failed attempts to sync data with a variety of Data Sync job methods it was eventually confirmed by AWS that this process would not work.
“Although a limit increase has been applied to increase the number of files that you can transfer using the Datasync service, there is still a limit that applies on the max number of files per folder which is 5 Million. Due to this, you are still facing this error on your end. “ — AWS Support
It was disappointing that the Data Sync limits documentation did not cite the files per folder (prefix) limitation.
We now found ourselves in a position where we were well into the implementation process, these were the last two important buckets, time was becoming more sensitive and we had to change strategies by identifying another solution with the hope of it being able to overcome the presented problems.
S3 BATCH REPLICATION TO THE RESCUE
On the 8th of February 2022 AWS released a new replication feature called S3 Batch Replication. This solution was not available during our initial investigation stage hence not considered as an implementation offering. When reviewing the media release, we became excited as we read the following quote:
“You can use S3 Batch Replication to backfill a newly created bucket with existing objects, retry objects that were previously unable to replicate, migrate data across accounts, or add new buckets to your data lake. S3 Batch Replication works on any amount of data, giving you a fully managed way to meet your data sovereignty and compliance, disaster recovery, and performance optimisation needs.”
The key terms here were, “existing objects” and “any amount of data”. These were the exact parameters we needed in a solution to solve our current challenge. Although we were excited that we may have found a theoretical solution, we had to engage in the practical implementation to be convinced.
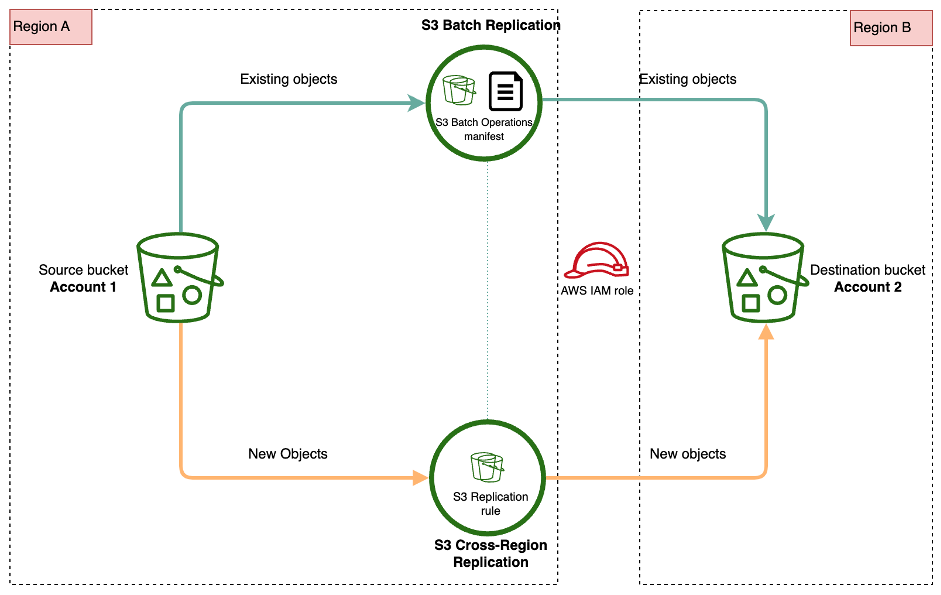
S3 Batch Replication works in combination with existing replication. This was convenient for us since we already had replication configured on the specified buckets. The existing replication ensures new objects in the source are copied to the destination.
A batch replication job hooks into the existing replication functionality but first compiles a manifest of all existing objects in the source bucket. A manifest can be understood to be a snapshot of all prefixes and objects that exist in a bucket at a given time.
Any new objects placed into the source bucket once the manifest compilation begins will not be applied to the manifest but will be handled by the existing replication function.
Once the manifest compilation is complete, the batch replication process can begin transferring the prefix and objects listed in the manifest. Our testing of the process was successful with a fair amount of data but we were unsure of how this solution would behave with the large amount of data we needed to transfer.
We were pleasantly surprised. For our use case, this solution worked as expected on our European and United States large buckets, taking ~4.5 and ~3.5 days respectively. All objects replicated without errors.
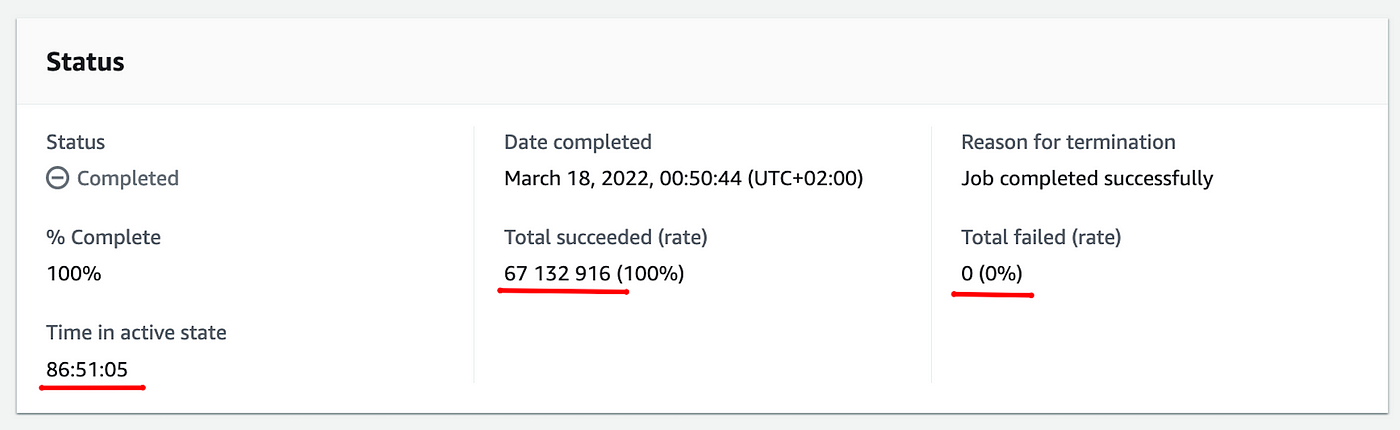
The output of the successful Batch Replication job in our United States region. Successfully transferring ~67 million objects in ~86 hours.
CONCLUSION
The successful implementation of this solution, with all the presented challenges, was a huge win for us in terms of keeping to our overall modernisation roadmap. It ensured that the other modernisation implementations that relied on this data being in the correct location could continue on schedule.
Becoming intimately familiar with a core AWS service is most definitely advantageous for future projects and assignments but lessons learnt regarding the importance of agility and persistence without compromising stability were invaluable.
As Kurtosys moves even further into the infinite world of technology modernisation these lessons will cultivate a culture of service excellence in an attempt to provide maximum customer, employees and stake holder value.