The AWS Global Infrastructure
Amazon Web Services (AWS) has a footprint on six of the seven continents of the world.


Amazon Web Services (AWS) has a footprint on six of the seven continents of the world. This allows customers of AWS to deploy resources in locations that suite their specific needs and allowing users the ability to diversify resources in multiple regions for high availability and disaster recovery purposes. This short blog will focus on the global infrastructure of AWS, including regional frameworks.
This post is part of a 101 series on AWS. If interested, checkout the other posts in this series:
- AWS Identity and Access Management
- AWS Authentication and Authorization with Policies
- AWS VPC fundamentals
Global Infrastructure
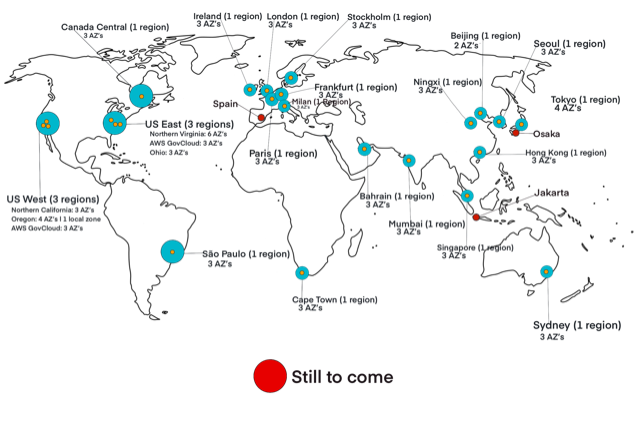
AWS’s global infrastructure comprises of what is known as regions and availability zones. On the above map, the regions are represented by the yellow dots. Currently, there are 24 launched regions, three announced regions and 77 availability zones. The most recent region to come online as of August 2020, was Cape Town, South Africa. The regions still to come are Spain, Osaka in Japan and Jakarta, Indonesia. Most regions comprise of three or more availability zones with Beijing being the only region with two availability zones. AWS also offers a Content Delivery Network (CDN) called Cloudfront. The service amounts to 216 points of presence comprising of 205 edge locations and 11 regional edge caches.
Regions and Availability Zones
Cloud providers use the terms "region" and "availability zone" in a different context and it’s important to understand how AWS uses these terms to describe its infrastructure.
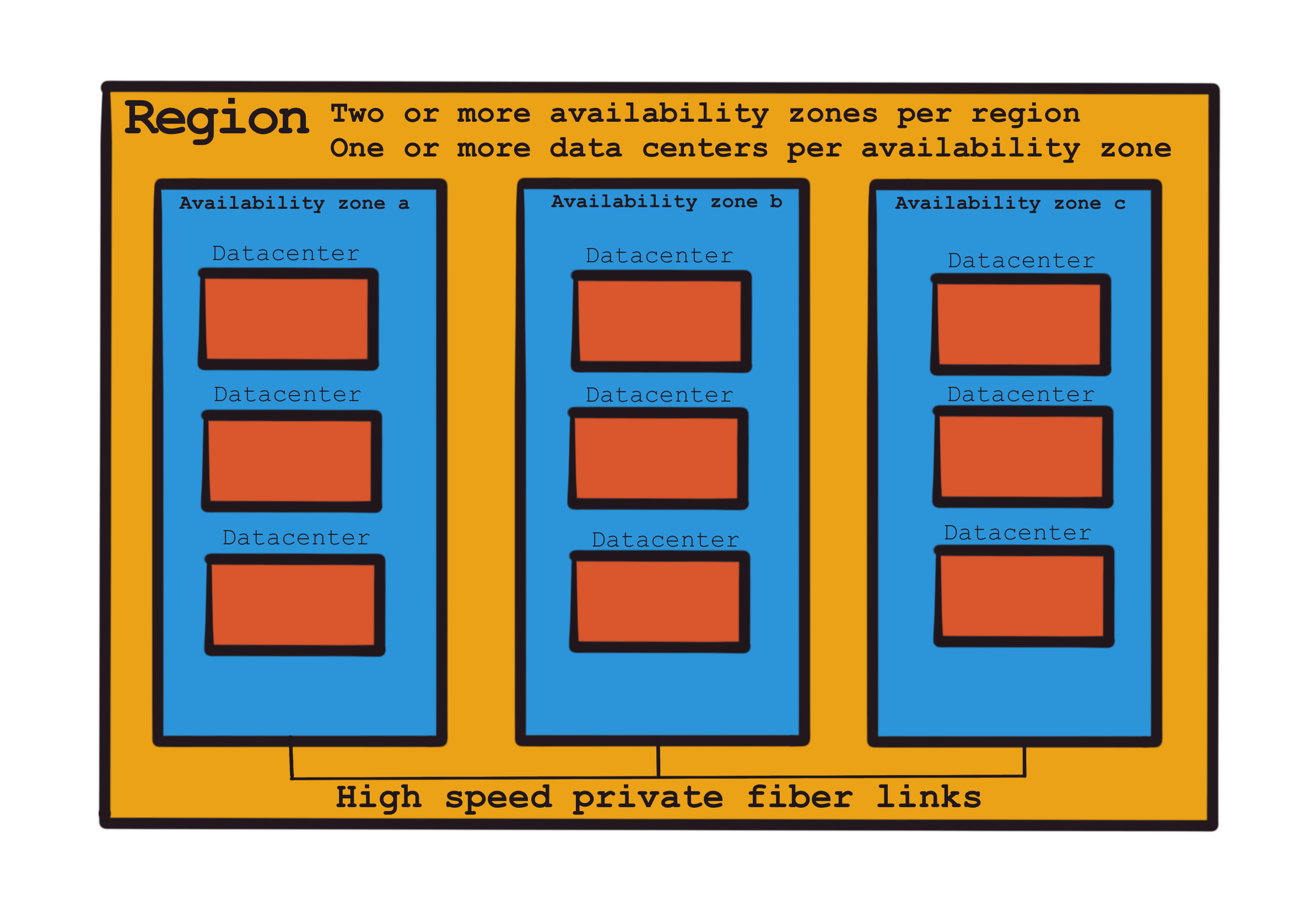
A region is a geographical location around the world where clusters of data centers are found. These clusters of datacenters are called availability zones. Each region will have three or more availability zones. Each availability zone will comprise of one or more datacenters. AWS’s largest datacenter has over 300 000 individual servers and the largest availability zone has 14 datacenters. Within a region, availability zones are positioned close enough to allow synchronous operations with a latency of between one and two milliseconds between each availability zone. This allows synchronous replicational operations between services, for example database servers, as if they were in the same datacenter. This is important, as it is recommended that resources are deployed to multiple availability zones to ensure high availability of services.
The reason that three or more availability zones are accessible and why it is recommended to deploy services in at least three availability zones is to mitigate down time if access to one or more availability zones are denied for any reason. This is illustrated in the diagram below.
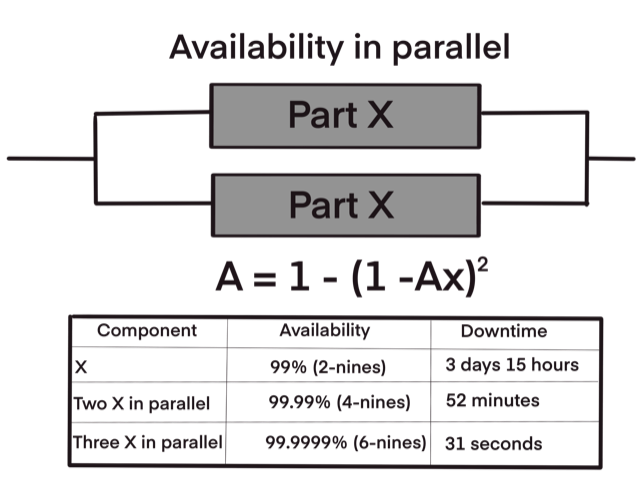
Downtime can be described as a deployed service that is out of action or unavailable for use. An analogy can be a service elevator in a building. If the building comprises of only a single elevator and that elevator is out of order, rapid access to all floors in the building are unavailable and the tedious task of using the stairs is the only option.
If this single elevator has an availability of 99%, over a period of one year it will be unavailable for 3 days and 15 hours. An availability of 99% may sound acceptable but it is unsatisfactory when this analogy is shifted to the realm of modern enterprise internet applications. Now, say a second elevator was added to the building, in parallel to the first, with the same percentage of availability, the downtime drops to 52 minutes over the same period of a year. Adding a third in parallel, downtime is reduced to 31 seconds. This is because, statistically, the chance of all three elevators being out of order at the same time becomes highly improbable (however not impossible) and will ensure an availability of 99.9999% or what is commonly known as six nines uptime.
This illustrates the fact that the more services you run in parallel the better. When having more than three in parallel, however, the number of seconds one can shave begins to taper off. This concept is the main reason why AWS aims to always have three availability zones in each region.
Conclusion
I hope the reader has benefitted from this brief presentation on the concept of AWS regions and availability zones and why availability zones are designed the way that they are. Readers are encouraged to comment with their own contribution to the topic, general feedback and thoughts on anything they feel I have missed or stated incorrectly.